SHA1算法源码分析
一、SHA1明文处理
1. C调用SHA1哈希方法
1
2
3
4
5
6
7
8
| SHA1Context ctx;
SHA1Context* pCtx = &ctx;
SHA1Reset(pCtx);
SHA1Input(pCtx, (const uint8_t*)"Hello SHA1", strlen("Hello SHA1"));
uint8_t digst[SHA1HashSize];
SHA1Result(pCtx, digst);
for (int i = 0; i < SHA1HashSize; i++)
printf("%02x", digst[i]);
|
2. 明文处理
SHA1的数据填充方式与MD5的一样:
- 在原始数据后添加一个1比特
- 在1比特后填充比特0,使其长度接近但不超过448位
- 最后使用64位二进制数表示原始数据长度,附件在末尾
填充当中与MD5唯一的区别就是:64位数据长度按照大端序存放
二、SHA1主要流程
1. SHA1Context结构体
1
2
3
4
5
6
7
8
9
10
| typedef struct SHA1Context {
uint32_t Intermediate_Hash[SHA1HashSize / 4];
uint32_t Length_Low;
uint32_t Length_High;
int_least16_t Message_Block_Index;
uint8_t Message_Block[64];
int Computed;
int Corrupted;
} SHA1Context;
|
2. 初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| int SHA1Reset(SHA1Context *context)
{
if (!context) {
return shaNull;
}
context->Length_Low = 0;
context->Length_High = 0;
context->Message_Block_Index = 0;
context->Intermediate_Hash[0] = 0x67452301;
context->Intermediate_Hash[1] = 0xEFCDAB89;
context->Intermediate_Hash[2] = 0x98BADCFE;
context->Intermediate_Hash[3] = 0x10325476;
context->Intermediate_Hash[4] = 0xC3D2E1F0;
context->Computed = 0;
context->Corrupted = 0;
return shaSuccess;
}
|
对比于MD5,SHA1初始化向量用了5个,其那四个与MD5一致。这个也是SHA-1的魔改点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| int SHA1Input(SHA1Context *context, const uint8_t *message_array, unsigned length) {
if (!length) {
return shaSuccess;
}
if (!context || !message_array) {
return shaNull;
}
if (context->Computed) {
context->Corrupted = shaStateError;
return shaStateError;
}
if (context->Corrupted) {
return context->Corrupted;
}
while (length-- && !context->Corrupted) {
context->Message_Block[context->Message_Block_Index++] =
(*message_array & 0xFF);
context->Length_Low += 8;
if (context->Length_Low == 0) {
context->Length_High++;
if (context->Length_High == 0) {
context->Corrupted = 1;
}
}
if (context->Message_Block_Index == 64) {
SHA1ProcessMessageBlock(context);
}
message_array++;
}
return shaSuccess;
}
|
使用SHA1Input函数将待加密的明文传入后,会先将明文按照512bit进行分组,然后512bit中的每字节存入MessageBox_Block当中,如果MessageBox_Block已经填满,则先进行一次SHA1的运算,之后继续遍历。
如果输入的原始数据过长,超过了**$2^{64}-1$**位的话就报错。
4. SHA-1运算函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| void SHA1ProcessMessageBlock(SHA1Context *context) {
const uint32_t K[] = {
0x5A827999,
0x6ED9EBA1,
0x8F1BBCDC,
0xCA62C1D6
};
int t;
uint32_t temp;
uint32_t W[80];
uint32_t A, B, C, D, E;
for (t = 0; t < 16; t++) {
W[t] = context->Message_Block[t * 4] << 24;
W[t] |= context->Message_Block[t * 4 + 1] << 16;
W[t] |= context->Message_Block[t * 4 + 2] << 8;
W[t] |= context->Message_Block[t * 4 + 3];
}
for (t = 16; t < 80; t++) {
W[t] = SHA1CircularShift(1, W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16]);
}
A = context->Intermediate_Hash[0];
B = context->Intermediate_Hash[1];
C = context->Intermediate_Hash[2];
D = context->Intermediate_Hash[3];
E = context->Intermediate_Hash[4];
for (t = 0; t < 20; t++) {
temp = SHA1CircularShift(5, A) +
((B & C) | ((~B) & D)) + E + W[t] + K[0];
E = D;
D = C;
C = SHA1CircularShift(30, B);
B = A;
A = temp;
}
for (t = 20; t < 40; t++) {
temp = SHA1CircularShift(5, A) + (B ^ C ^ D) + E + W[t] + K[1];
E = D;
D = C;
C = SHA1CircularShift(30, B);
B = A;
A = temp;
}
for (t = 40; t < 60; t++) {
temp = SHA1CircularShift(5, A) +
((B & C) | (B & D) | (C & D)) + E + W[t] + K[2];
E = D;
D = C;
C = SHA1CircularShift(30, B);
B = A;
A = temp;
}
for (t = 60; t < 80; t++) {
temp = SHA1CircularShift(5, A) + (B ^ C ^ D) + E + W[t] + K[3];
E = D;
D = C;
C = SHA1CircularShift(30, B);
B = A;
A = temp;
}
context->Intermediate_Hash[0] += A;
context->Intermediate_Hash[1] += B;
context->Intermediate_Hash[2] += C;
context->Intermediate_Hash[3] += D;
context->Intermediate_Hash[4] += E;
context->Message_Block_Index = 0;
}
|
这个跟md5的轮函数就很相似了,只不过md5的直接将每一步用宏写出来,而这里使用的是循环。
SHA1和MD5一样,也有分组,只不过MD5的分组是M0~M15总共16个分组,而SHA1则是80个分组,W0~W15使用原始数据进行分组,后面的分组都是经过前面的分组运算之后进行循环左移1位(不进行左移就是SHA0了,有安全性问题)产生的。
通过轮函数的运算之后再和开始的初始化向量相加。
轮函数如下:
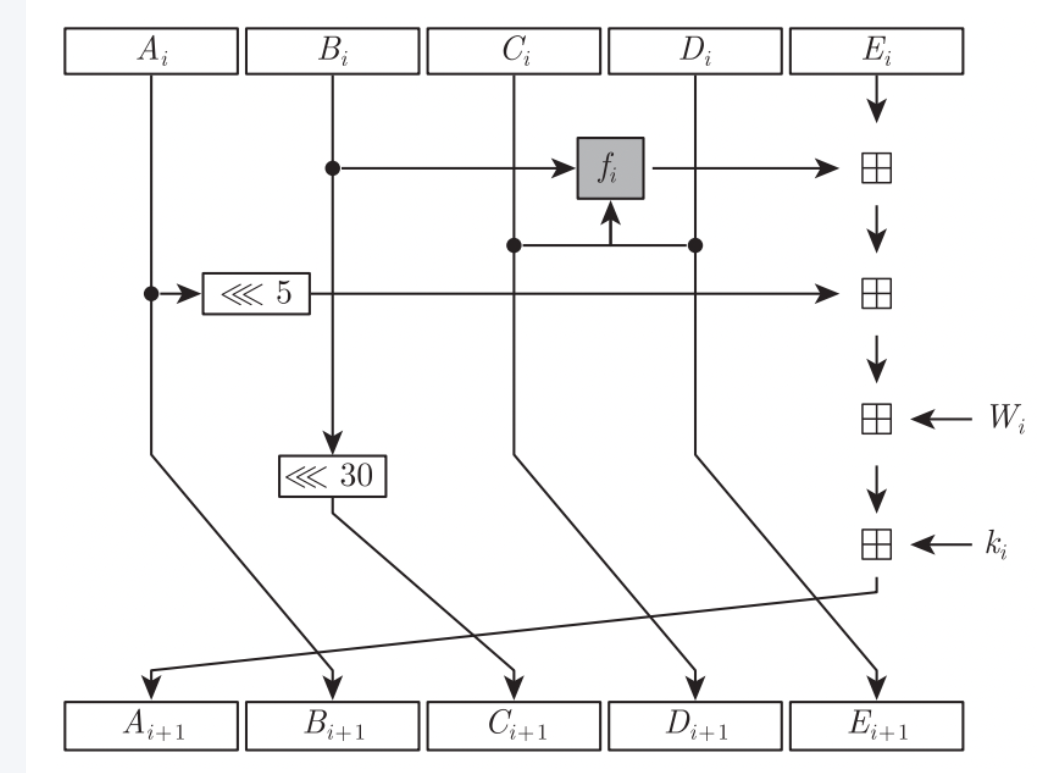
5. SHA1Result函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| int SHA1Result(SHA1Context *context, uint8_t Message_Digest[SHA1HashSize]) {
int i;
if (!context || !Message_Digest) {
return shaNull;
}
if (context->Corrupted) {
return context->Corrupted;
}
if (!context->Computed) {
SHA1PadMessage(context);
for (i = 0; i < 64; ++i) {
context->Message_Block[i] = 0;
}
context->Length_Low = 0;
context->Length_High = 0;
context->Computed = 1;
}
for (i = 0; i < SHA1HashSize; ++i) {
Message_Digest[i] = context->Intermediate_Hash[i >> 2]
>> 8 * (3 - (i & 0x03));
}
return shaSuccess;
}
|
该函数会先判断SHA1是否已经计算完成,如果还未计算完成,则会先进行SHA1PadMessage,填充后计算一轮,然后再将最终的Intermediate_Hash值以大端序的格式存储到MEssage_Digest摘要当中。
SHA1PAdMessage实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| void SHA1PadMessage(SHA1Context *context) {
if (context->Message_Block_Index > 55) {
context->Message_Block[context->Message_Block_Index++] = 0x80;
while (context->Message_Block_Index < 64) {
context->Message_Block[context->Message_Block_Index++] = 0;
}
SHA1ProcessMessageBlock(context);
while (context->Message_Block_Index < 56) {
context->Message_Block[context->Message_Block_Index++] = 0;
}
} else {
context->Message_Block[context->Message_Block_Index++] = 0x80;
while (context->Message_Block_Index < 56) {
context->Message_Block[context->Message_Block_Index++] = 0;
}
}
context->Message_Block[56] = context->Length_High >> 24;
context->Message_Block[57] = context->Length_High >> 16;
context->Message_Block[58] = context->Length_High >> 8;
context->Message_Block[59] = context->Length_High;
context->Message_Block[60] = context->Length_Low >> 24;
context->Message_Block[61] = context->Length_Low >> 16;
context->Message_Block[62] = context->Length_Low >> 8;
context->Message_Block[63] = context->Length_Low;
SHA1ProcessMessageBlock(context);
}
|
该函数开始先判断Message_Block当中是否大于55字节,如果大于则后续不够填充数据长度,则先填充0x80和一堆0,先扩充至512位,进行一次运算先。运算完成后会重现填充0,直到填满56位。
如果没有大于55字节,则先填上0x80,然后填充字节0,最后填上数据长度到末尾(这里也是大端序方式填充),最后计算。
可以看到这个SHA1与md5大致的流程还是满相似的。
