
01_MD5源码分析
01_MD5源码分析
一、MD5明文处理
1. C实现的MD5算法使用
1 | MD5_CTX context; |
2. MD明文处理大致过程
首先对明文进行hex编码:xiaojianbang ==> 78 69 61 6f 6a 69 61 6e 62 61 6e 67。然后会将明文填充到448bit,填充的时候先填一个比特位,再填0,将明文扩展到448bit。
接着就是附加消息长度:用64bit表示消息长度,这里的长度是指明文的比特位数量,然后将长度转小端序之后拼接。
最后明文会处理成以下形式:
1 | |<----------------- 448 bit ----------------->|<------64bit--------->| |
加起来就是512bit
注意事项:
- MD5输入数据无限大,不可能一起处理,需要分组
- MD5分组长度为
512bit,数据需要处理到512的倍数,所以需要填充 - 填充的位数为
1-512bit,如果明文长度刚好为448bit,那么就填充512bit
这里第三点,为什么明文长度刚好为448时,要填充512bit的原因是这样的: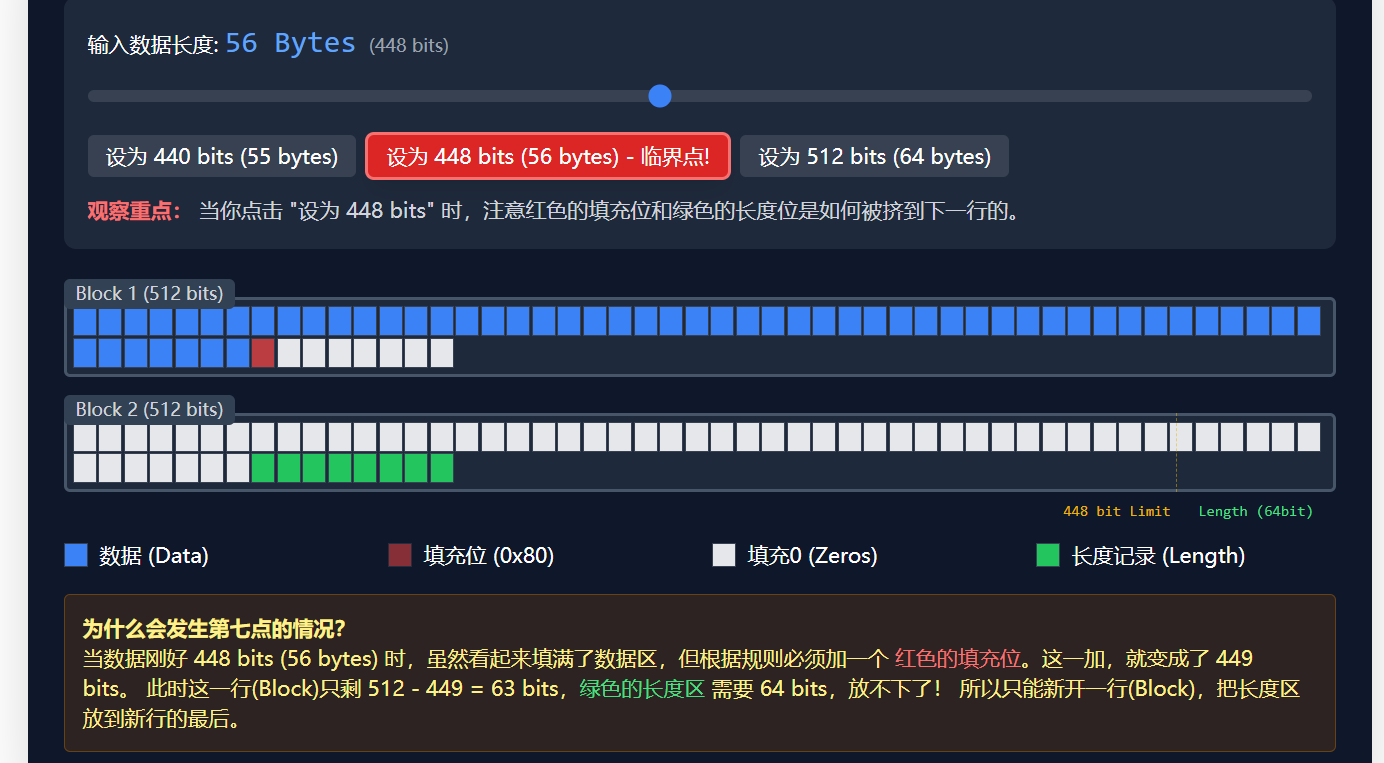
二、MD5初始化常量
MD5的初始化使用的是MD5Init(MD5_CTX *context)这个函数:
1 | void MD5Init(MD5_CTX *context) { |
这个初始化函数就是将MD5_CTX当中的count清零,给state初始化赋值,这个context->state赋值,这个就是state就是md5的初始化向量。标准md5的魔术就是这样,一般开发人员喜欢修改这些值来达到魔改md5的目的。
三、MD5的Transform
1. Transform的基本步骤
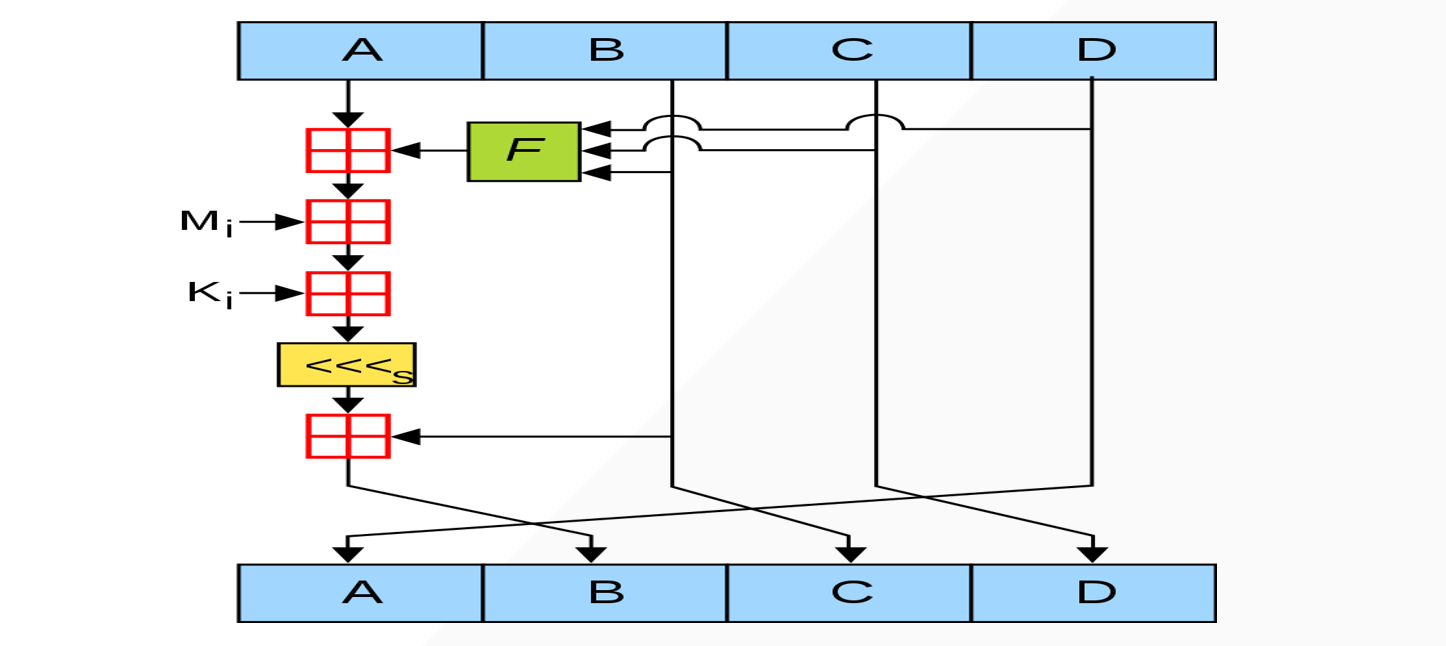
这是MD5算法中最核心的轮循环运算。首先方框是加法,<<<是循环位移,ABCD对应的就是ctx当中的state。
每一轮都会把旧的D给新的A,旧的B给C,旧的C给D。然后将旧的A通过运算之后给新的B,也就是每一次运算都只处理一个
DWORD的值。A到B的过程如下:
B = ((A + F(B,C,D) + Mi + Ki) <<< S) + B最后经过这四个初始化常量不断变化后的值,拼接得到最终的摘要结果
2. Transform算法流程
1 | void MD5Transform(unsigned int state[4], unsigned char block[64]) { |
这里通过64轮的变换之后重新拼接成一个128位的值,也就是md5值,这几个FF, GG, HH, II是一个宏,具体定义如下:
1 |
所以一开始的单轮的转换图,当中的F函数其实有四种,分别是F, G, H, I。
3. MD5Encode与MD5Decode
1 | void MD5Encode(unsigned char *output, unsigned int *input, unsigned int len) { |
MD5Encode:的功能就是将DWORD在内存中的排布存放到字节数组当中,例如DWORD的0x12345678按照内存排布转成字节数组就是:0x78 0x56 0x34 0x12MD5Decode:将字节数组转成DWORD,与上面函数操作相反
4. MD5Update实现
1 | void MD5Update(MD5_CTX *context, unsigned char *input, unsigned int inputlen) { |
count当中存放的是明文的总位数,count[0]存放低四位,count[1]存放高四位。
5. MD5Final实现
1 | void MD5Final(MD5_CTX *context, unsigned char digest[16]) { |
这里会将所需要填充的位数求出来,然后使用MD5Update进行最后的填充,然后再进行Transfrom。最后将context当中运算完成的state进行拼接,就是md5的哈希结果。